
This is the first in a series of articles to help call centre and securitySecurity is one of three key measures of Call Centre Security process performance. It is usually expressed as the likelihood that the process allows someone who isn't who they claim to be to access the service (False Accept). leaders understand the risks of synthetic speech (aka Deep Fake) to their operations and organisations. For their purposes, the media, technology vendors (on both the generation and detection side) and lawmakers have created enormous fear, uncertainty and doubt (FUD). I aim to help readers cut through this to make appropriate decisions for their organisations.
Introducing a Hierarchy of Attack Methods
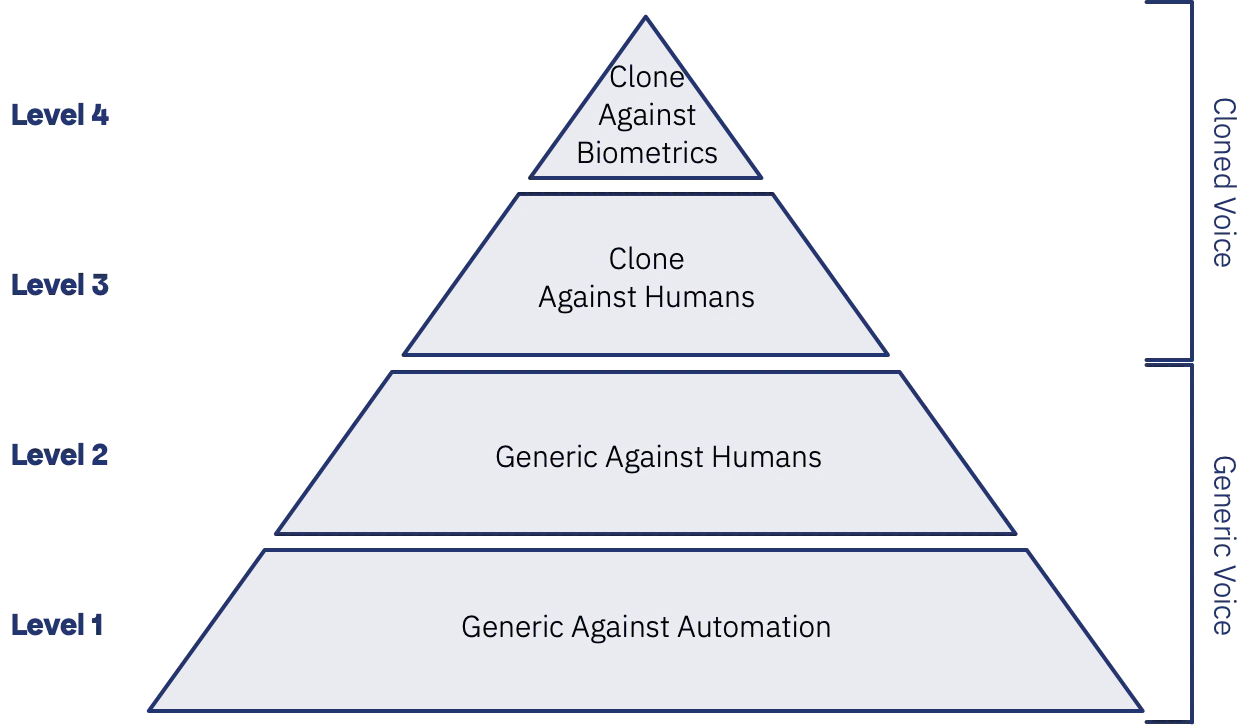
First, many parties conflate different attacks and risks into the same thing. To provide you with a clear understanding, I will introduce a hierarchy of the different threats before exploring their details, impacts and approaches to mitigation in subsequent articles. Starting at the simplest and building to the most complex, the four levels are:
Level 1 - Generic Synthetic Speech Against Automated Telephone Systems
For years, attackers have exploited telephone self-service applications using touch-tone (DTMF) to validate data, extract customer information and even initiate fraudulent transactions. The increasing use of speech-driven applications has necessitated speech (often their own), but synthetic speech allows them to automate and scale these attacks.
As the attack is against an automated system, the voice doesn't need to be that good, as no human will ever listen to it. Due to these systems' repeated and predictable nature, these attacks scale easily, so they could easily be used to validate thousands of account details before anyone noticed. Finally, in systems protected by one-time passcodes, this approach allows fraudsters to socially engineer the OTP from the genuine customer and input it into the system in an automated way.
Level 2 - Generic Synthetic Speech Against Your Customers and Employees.
The "stock" voices of modern synthetic speech are really good and can, with a little work, pass the "sound-like" human ear test, particularly when accounting for the lower fidelity of telephone calls.
Using these voices, attackers can easily mask their identities and sound like locals to avoid leaving evidence and reduce target suspicion. They can then employ traditional social engineering techniques to obtain personal information, circumvent controls, and authorise transactions.
At their simplest level (2a), these conversations are just a collection of pre-prepared phrases triggered by the attacker using a soundboard or similar software. These attacks will likely be effective against call centre agents as the conversation flow, whilst not automated like an IVR, is very predictable after a few reconnaissance calls.
However, to automate and scale these attacks (2b), attackers need to account for the less predictable nature of human-to-human conversations. They need to employ speech recognition and rules-based or "AI-powered" logic to make the conversation flow, and the conversation needs to be responsive. As fraud of this type is a numbers game, the conversation doesn't have to be that convincing to pay off, so attackers don't have to be perfect.
Level 3 - Cloned Voice Synthetic Speech Against Your Customers or Employees
When attackers need to increase a target's confidence and use more sophisticated social engineering techniques to circumvent other controls, they often need to sound like someone specific, known to the target, such as a relative or a superior. Voice cloning allows attackers to take a sample of a subject's voice and create a synthetic version that they can get to say whatever they want.
The media often refers to this type of attack as Deepfake, and the audio produced can sound very realistic, just like the real speaker. As a more complex attack, it obviously takes more effort, and we'll explore this attack chain in more detail in later articles.
The most easily accessible example of this today is Apple's Personal Voice and Live Speech feature in iOS - Is Apple’s new Personal Voice and Live Speech a security risk?
Level 4 - Cloned Voice Against Biometric Authentication Schemes
The final and most sophisticated attack requires attackers to create a sufficiently good voice clone of their target so that it is indistinguishable during biometric comparison. Attackers could use this to access an account or authorise transactions protected by a Voice Biometric authenticationAuthentication is the call centre security process step in which a user's identity is confirmed. We check they are who they claim to be. It requires the use of one or more authentication factors. scheme, most often in the call centre.
The technology exists and the attack chain is similar to 3 above which we'll explore in a later article.
This has so far been the most popular with journalists in the US, UK and Australia, defeating bank and government authentication schemes:
- JP Morgan Chase - 23 April 2023 - https://www.wsj.com/articles/i-cloned-myself-with-ai-she-fooled-my-bank-and-my-family-356bd1a3?mod=tech_lead_pos5
- Centrelink - 16 Mar 2023 - https://www.theguardian.com/technology/2023/mar/16/voice-system-used-to-verify-identity-by-centrelink-can-be-fooled-by-ai
- Lloyds Banking Group - 23 Feb 2023 - https://www.vice.com/en/article/dy7axa/how-i-broke-into-a-bank-account-with-an-ai-generated-voice
Key Differences
As you can see, there are several clear distinctions here:
- Generic voice versus specific (cloned) voices - Level 1+2 v Level 3+4
- Sounding alike versus being alike - Level 3 v 4
- Manual versus automated - Level 2a and 3a v 2b and 3b
Implications for Call Centres and How to Mitigate
We've zeroed in on the synthetic speech, but this is just one method available to attackers in these scenarios. Many require far less effort to achieve their objectives, so it's unsurprising that we only see Level 1 attacks at any scale in the wild. Of course, as other attack methods are countered and as these solutions become easier to deploy, the balance will change, so organisations need to understand and be prepared for the future.
In the next article, I'll examine the implications of Level 1 and 2 attacks for enterprises and their customers. Subscribe now to make sure you don't miss it, but if you can't wait, then check out my discussion with Haydar Talib of Microsoft here: Battling Deepfakes and Synthetic Voices: Safeguarding Voice Biometrics Systems