
As part of its iOS 17 release, Apple announced a new accessibility feature called Personal Voice. When combined with Live Speech, this feature enables someone at risk of losing their voice to create a synthesised version that they can use during calls and conversations on their iPhone, iPad and Mac computers. Whilst clearly designed for accessibility, the announcement, against a backdrop of media attention on the threat from deep fake voices, naturally raises questions about how this feature might be used more nefariously, so I took an in-depth look at it to find out more.
Personal Voice Setup
Setting up a Personal Voice requires a modern iPhone, iPad or Mac running the latest version of Apple’s operating systems: iOS 17, iPadOS 17 or MacOS Sonoma. The set-up process is simple and well-designed, taking between 15 and 20 minutes to complete. Accessed through the accessibility menu in the settings app, the process guides the user through providing 150 different samples of their voice using a randomised mixture of statements, questions, exclamations and common phrases. The randomisation does produce some odd context shifts, such as “No matter the time of day, I’ll happily eat a cookie”, leading to “It’s part of the inch-pound system of measurement which is used in the United States”, so I did find myself needing to go back and repeat a few.
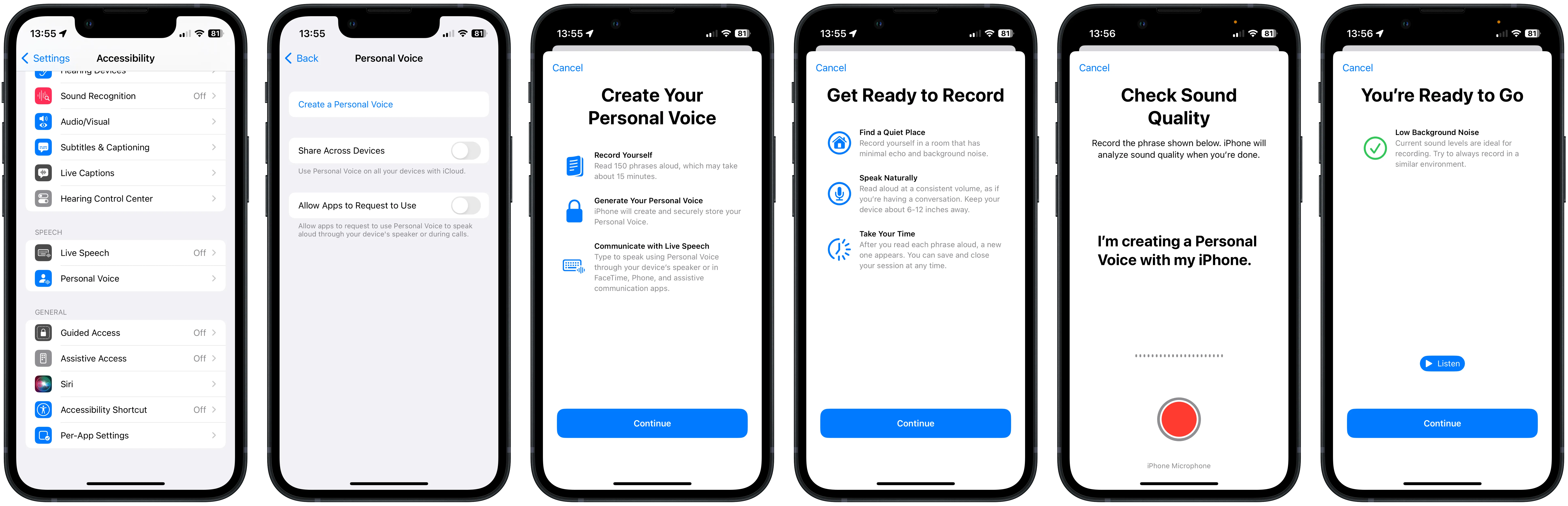
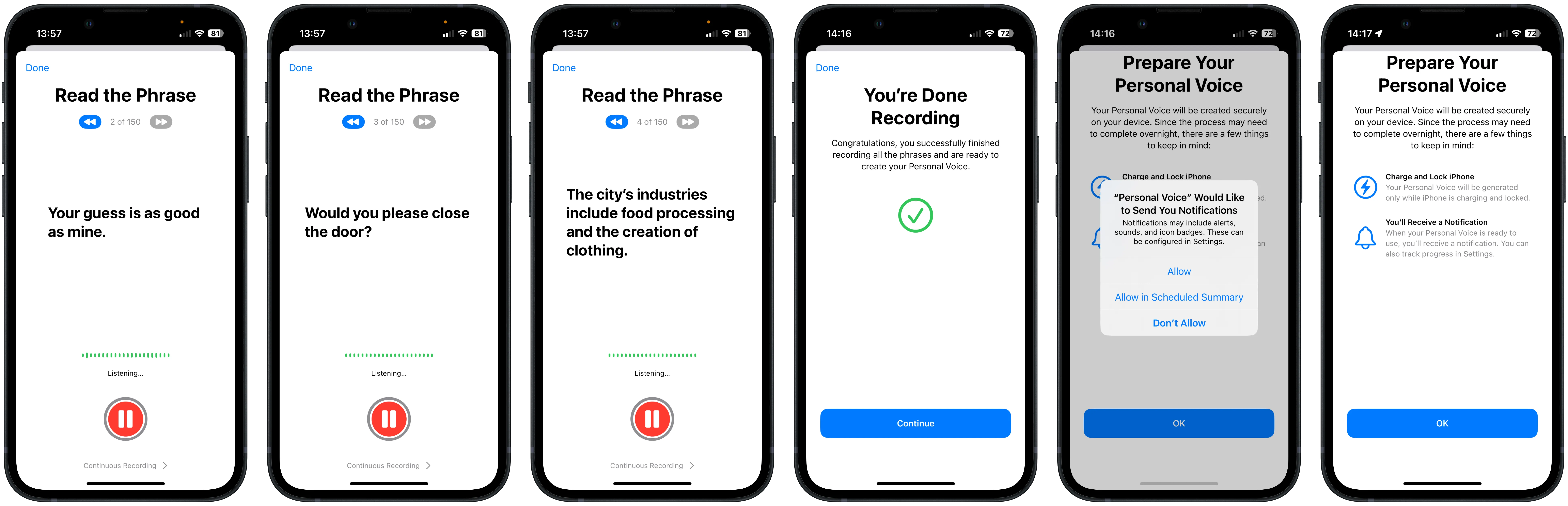
When the process is complete, the samples are processed locally on the device to create the Personal Voice. Likely due to the intensive processing required, this only happens when the device is plugged in and locked. In my case, it was completed overnight, but even in the best case with the most modern phone, it will probably take at least 6 hours. You get a notification when it’s set up and ready to use.
Using Personal Voice with Live Speech
To use your Personal Voice, you need to enable the Live Speech option from the same part of the accessibility menu. You can also set up favourite phrases or select one of the default voices here. Live Speech can then be enabled anywhere by triple-clicking the side button.
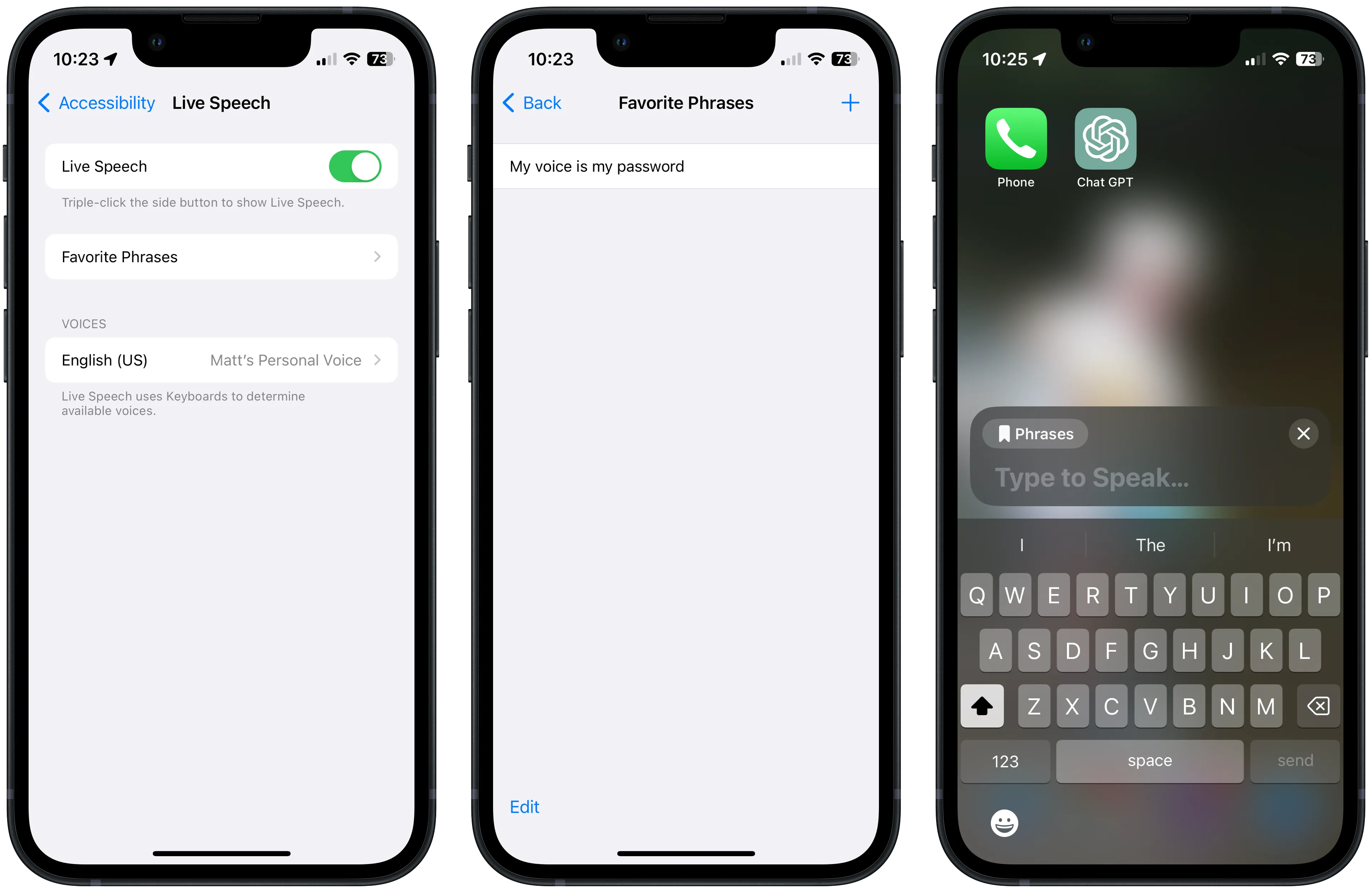
Once enabled, Live Speech pops over any running application or the Home Screen. You can then select a favourite phrase or type with the keyboard before pressing send or enter, which will play through the currently selected output device. This means that you can also capture or into a phone or audio call if in progress.
Verdict
I think the generated voice is pretty good, relatively speaking; it has the right tone and, in very short snippets, doesn’t sound too unnatural, but it does lack the cadence and inflexion of a natural voice. You can hear for yourself:
As you can hear, there is little chance that today's Personal Voice is going to be mistaken for a genuine speaker. Apple has, consistent with the accessibility use case, clearly prioritised speed of utterance generation over quality, training and model creation time. It is nearly instantaneous, allowing the user to respond to questions rapidly and changing context.
Privacy and Security Features
True to its privacy-centric brand image, Apple has thought through the securitySecurity is one of three key measures of Call Centre Security process performance. It is usually expressed as the likelihood that the process allows someone who isn't who they claim to be to access the service (False Accept). implications of Personal Voice and Live Speech pretty well:
- Local Processing - The data is all held locally on the device, so it can not be lost in a mass data breach.
- Biometric Lock - The Personal Voice generation and management features are secured by Face or TouchID, and using Live Speech with a personal voice requires the device to be unlocked so a casual device thief cannot get access.
- Limited Sharing - Personal Voices can be shared across devices belonging to the same iCloud account, and the original utterances can be exported, but there does not appear to be a way to transfer the voice to another device.
- Randomised Phrases - Whilst each voice requires 150 utterances, we estimate that at least 350 phrases could be used. Whilst some phrases might be heard in common parlance, many are exceedingly odd, making it close to impossible for them to be gathered from social media or for a user to be unwittingly duped.
- ConsentConsent is a step in the registration process where a user provides permission to process their biometric data before enrolment in a Voice Biometric system in a way which complies with applicable data protection and privacy legislation. Statement - Before starting the generation process, the user must say, “I’m creating a Personal Voice with my iPhone”, which adds a further control step, although it’s unclear whether this is ever checked against the subsequent samples.
What are the risks?
To evaluate the risks from Personal Voice and Live Speech to individuals and enterprises, I evaluated enterprises and individuals as separate attack surfaces but with somewhat related attack vectors.
Automated Social Engineering
In this attack, a synthetic voice is used with speech recognition to automate social engineering by telephone. The synthetic voice does not have to sound like a specific person, just natural enough to be believed to be human. The automation allows attackers to target hundreds or thousands of individuals with relatively little marginal effort. Whilst it’s unlikely that consumers will believe a Personal Voice is a real person, the lack of any automation or API prevents the use of Personal Voice in this attack.
Targeted Individual Attack
In this attack, a synthetic voice is used to trick an individual into believing that they are speaking to someone they know in order to extract security information for use elsewhere, blackmail or demand a ransom. This requires that the personal voice sounds like the specified individual. Even if the victim did believe the Personal Voice was real, the amount of audio required to create the Personal Voice and its unpredictability makes it very difficult for the attacker to create the voice. In practice, very few Apple users are going to go through the effort of creating a Personal Voice, and for those that do, Apple's design limits the risk of a voice being stolen or misused other than if the device itself is lost.
Enterprise Business Process Compromise
In this scenario, a synthetic voice is used to trick an employee into completing a process step, believing it has been authorised by a known colleague. Similar to the targetted individual attack, this requires a Personal Voice to be created for the specified individual, which is unlikely to be easy with the amount of audio required. It should be noted that several research teams have claimed they can create synthetic voices with just a few seconds of audio from the target speaker. Apple's Personal Voice is clearly not in this category.
Automated Enterprise Customer Service
This attack uses a generic synthetic voice to target enterprise call centres to extract personal information at scale. Similar to the attack on an individual, it does not require a specific voice but does require tools to allow automation. Whilst Apple's Personal Voice has some hooks to allow App developers to access, it's very unlikely that this will allow the kind of scalable attack that some cloud-based synthetic speech services provide.
Enterprise Voice Biometric Authentication
In this attack on enterprises using Voice BiometricsVoice Biometrics uses the unique properties of a speakers voice to confirm their identity (authentication) or identify them from a group of known speakers (identification). for customer authenticationAuthentication is the call centre security process step in which a user's identity is confirmed. We check they are who they claim to be. It requires the use of one or more authentication factors., a synthetic voice is created of a genuine customer through social engineering or using utterances available from social media. The synthetic voice is then used to trick a Voice Biometric authentication system into believing that it's the genuine user. In my limited testing, the speech quality was insufficient to fool these systems using short utterances, and I would expect that synthetic speech detectionSynthetic Speech Detection is a mechanism used to protect Voice Biometrics systems from presentation attacks using synthetic speech. It relies on detecting characteristics inherent in the text-to-speech (TTS) generation process. tools will be easily able to identify the common features of these voices. That said, even if the voice was of higher quality, the generation process for Personal Voice, compared to other synthetic speech services, makes it an extremely unlikely tool for attackers.
For a more in-depth discussion of the risks to Voice Biometric systems from synthetic speech and deep fakes, you should watch my Modern Security Community session on the subject Battling Deepfakes and Synthetic Voices: Safeguarding Voice Biometrics Systems.
Fake Media
In this attack, a synthetic voice is used to make public claims statements that the targeted individual would not have made or place them in compromising situations. When combined with video, this attack can seriously affect an individual's reputation and mislead public opinion. As with the other forms of attack, the quality of Personal Voice is unlikely to be good enough to fool humans, and the generation process makes it unlikely that individuals could be easily tricked into contributing utterances to create the Voice.
Conclusion
Whilst an excellent accessibility feature, the design and execution of Personal Voice creates very few risks for individuals or organisations deploying technologies such as Voice Biometrics. Apple could, of course, go even further to prevent nefarious use.
Apple has made no statements about watermarking Personal Voice so that its use can be specifically detected, although I suspect, given the company’s privacy and security focus, it may already include this feature. It would be good, however, if the means of detection were made publicly available so that Voice Biometric vendors, in particular, could ensure they can detect it.