
Advances in Speaker Recognition technology and increasing acceptance of conversational interfaces are allowing organisations to authenticate callers using the short utterances now obtained in natural language and speech driven self service applications, without the overhead of traditional active enrolmentEnrolment is a step in the registration process where specific utterances are requested from the user or previously acquired audio is used to create a Voice Biometric template (Voiceprint) for subsequent use in Authentication/Identification. processes. This approach will significantly increase the overall benefits of deploying Voice BiometricsVoice Biometrics uses the unique properties of a speakers voice to confirm their identity (authentication) or identify them from a group of known speakers (identification). for Speaker Recognition, and we expect it to make these solutions relevant to a far wider range of end users.
Voice Biometrics Deployment Approaches Today
In our recent post on the Challenges of Voice Biometrics Adoption in the Contact Centre, we identified the binary active or passive decision organisations faced, as a key reason why many don't go on to implement this technology despite the clear benefits. There is no doubt that Voice Biometrics can dramatically improve the securitySecurity is one of three key measures of Call Centre Security process performance. It is usually expressed as the likelihood that the process allows someone who isn't who they claim to be to access the service (False Accept)., efficiencyEfficiency is one of three measures of Call Centre Security process performance. It represents the actual and opportunity cost of the security process, for example the costs of agent time spent on manual authentication or the missed opportunity for self-service. and ease of use of contact centre and automated applications but today it is almost always deployed in one of two modes, both of which work but neither of which fully realise the opportunity:
- Active - Uses Text Dependent Voice Biometrics to authenticate callers in an automated application using a static (such 'my voice is my password'), or caller dependent (such as a mobile phone or other identifying numbers) passphrase. In most cases this passphrase is less than 1.5 seconds, so adds very little time from the caller's perspective. The major advantage of this approach is that it allows callers to access self service applications and eliminate the requirement for any authenticationAuthentication is the call centre security process step in which a user's identity is confirmed. We check they are who they claim to be. It requires the use of one or more authentication factors. when the call is connected to an agent. The disadvantage of this approach is that enrolment is generally automated, requiring the caller to verify their identity with an automated application at the start of the call, or be transferred back to an automated service at the end, and then record their passphrase multiple times. We call this approach active because it requires the caller to do something that is not contributing to fulfilling the reason for their call both during verification and registrationRegistration is the business process where a user is offered, consents to, and completes a Voice Biometric service enrolment.. As a result of this additional customer effort, we generally see lower overall levels of adoption than with the alternative (40-60%). Additionally, because the caller always says the same thing, this approach is also theoretically more vulnerable to presentation attacks using recordings.
- Passive - Uses Text Independent Voice Biometrics to authenticate callers as they speak to the agent. This approach compares how the caller generally speaks, as opposed to the way they speak a specific phrase. Therefore it typically requires more caller audio (3-15 secs), to achieve the same level of accuracy as the short passphrase used in Text Dependent technologies for verification and significantly longer for enrolment (40-60 secs). We call this approach passive because the caller does not have to do anything in addition to their reason for calling to establish their voiceprint or confirm their identity (although most jurisdictions require the customer consentConsent is a step in the registration process where a user provides permission to process their biometric data before enrolment in a Voice Biometric system in a way which complies with applicable data protection and privacy legislation. to this). The significant advantage of this approach is that the low customer effort drives much higher take up rates than the alternative (80-95%) and significantly improves the perceived customer experience. The inclusion of an agent in the verification process also makes presentation attacks using simple recordings less viable although more sophisticated synthetic voices still present a risk. The critical disadvantage is that by the time authentication is complete with the agent, any opportunity for automated self service has been lost, and the agent call can no longer be avoided.
[table id=1 /]
Nirvana - The Hybrid Approach
Larger organisations and those with significant value at risk in their phone channel can use either traditional approach depending on their specific circumstances, and the benefits will still outweigh the cost and complexity of implementation. Many others are put off by the reality of having to make this choice and the implications for benefit delivery. To justify the cost of the investment, many organisations need a solution that delivers both high adoption and the opportunity to avoid calls entirely through self service.
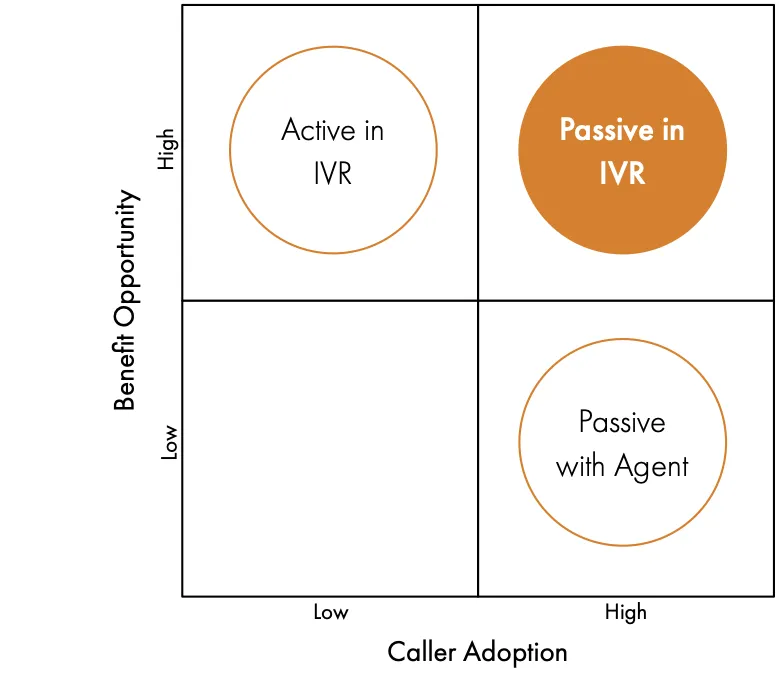
They want to authenticate customers using the short utterances provided to a typical open question or natural language automated system and therefore have the opportunity to provide self service options but without the significant customer effort required to enrol an active passphrase.
What's changed
The good news is that it is now possible for a significant proportion of callers who engage with a typical open question solution to have their identity confirmed using just their response to this question. Provided they have enrolled in a text independent voice biometric service during a previous agent conversation. There are several reasons why this approach is now viable when it hasn't previously been:
- Improved Biometric Performance - Continued investment in the performance of the underlying algorithms and the application of new methods, such as Deep Neural Networks, means that the accuracy and performance of text independent algorithms arsle now approaching those of text dependent ones. Multiple vendors in recent years have claimed that their solutions are capable of authentications with the type of utterances obtained from IVR solutions:
- NICE claims their Real Time AuthenticationAuthentication is the call centre security process step in which a user's identity is confirmed. We check they are who they claim to be. It requires the use of one or more authentication factors. solution had been enhanced to seamlessly create and utilise one voiceprint for each customer to deliver quick and efficient customer service across all voice channels, with no customer effort required.
- Pindrop claims their Deep Voice Engine enables deep analysis of short utterances like those obtained in the IVR and when combined with their PhonePrinting and behavioural analysis technologies as part of the Passport product to passively authenticate legitimate customers in the IVR or with the agent.
- Nuance claims their Lightning Engine means that a single human command to an IVR is enough for that system to understand who is talking and what it is they want in as quick as half a second.
- Natural Language IVRs - Thankfully, many organisations are replacing their touch tone based phone trees with natural language systems that use open questions to elicit the caller's reason for calling. The proliferation of good enough, accessible and cheap version of this technology, from the likes of Microsoft, Amazon, Google, Twilio and others will only accelerate this trend.
- Increased Utterance Length - Smart assistants, smart speakers and the increasing ubiquity of speech recognition technology has increased user acceptance and willingness to engage. Historically the majority of telephone channel users might have provided single word responses, or not engaged at all, but we are now seeing increasing length and levels of engagement in industries that deploy this technology
The reality
The unfortunate reality is that despite the opportunity and marketing hype from different vendors, we have not yet seen any real world end user implementations of this approach. Which we put down to four key factors:
- Lower verification success rates - The limited data available suggests that significant numbers of callers could be verified using this approach, but it's certainly not the 90-95% true accept rate we usually consider as the benchmark in traditional modes of operation. Most results we've seen optimistically report their short utterance performance at 3 seconds of audio, with success in the 75-90% range, yet in practice, most customer utterances remain below 2 seconds. Progress is, however, still being made and a focus on short utterance verification accuracy means that there are improvements with every new iteration of vendor products.
- Voice User Interface Design - Historically, to aid disambiguation of responses, typical application design was focused on keeping caller responses as short as possible. As this technology has improved, it is no longer as essential, so subtle changes in the wording and design of the application can be made to elicit longer responses from callers who are also becoming more accepting and used to conversational interfaces.
- Uniform Risk Appetite - Traditionally, organisations have favoured a single standard that must be achieved before any information can be disclosed, transaction captured, or query discussed. This continues to be the case with Voice BiometricsVoice Biometrics uses the unique properties of a speakers voice to confirm their identity (authentication) or identify them from a group of known speakers (identification). applications where re prompts for the passphrase can be used in TD applications and there is generally no shortage of audio in TI applications, so a single threshold has no material impact. In the case of short utterance verification; a small reduction in this standard or use of this test later in the call could allow dramatically more callers to proceed. Self service applications typically only provide access to low risk services, but as callers progress through their journey, more audio is acquired, which can increase the confidence that it is the real speaker. Even when capturing instructions for riskier transactions, it is only necessary to be highly confident of the caller's identity before the transaction is committed rather than before starting capture.
- Customer Journey Design - Whilst the match caller journey is easy to design there are still a significant number of callers who won't take this path because they didn't provide enough audio, any audio, or it simply didn't match at the required level of risk. All of these scenarios need to be catered for and attempts made to move them onto a more positive path. These journeys are new, but with skill can be mostly transparent to the caller.
Where next
Ultimately there is only a finite amount of data available in these short utterances, so whilst it appears likely that there is another iteration of the technology to go before we reach the point of diminishing returns, hoping that science is going to eliminate the problem is foolhardy.
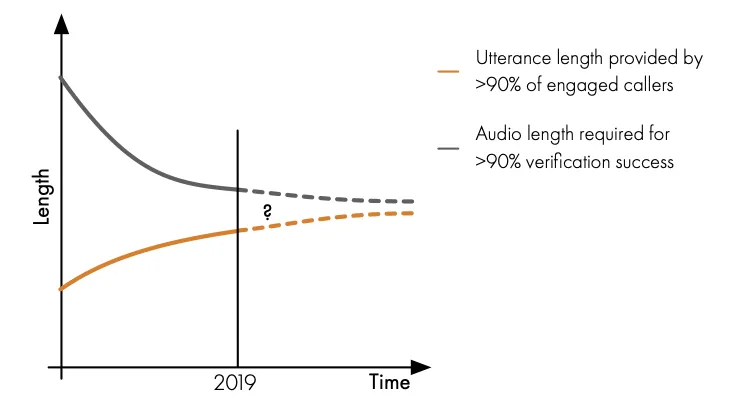
The above, theoretical, chart shows the reducing gap between the length of utterances provided and the amount of audio required to give high confidence results. We expect that while they will continue to get closer, they may never quite meet so the issues above will have to be addressed sooner or later. For this reason, we believe that the approach is good enough to implement today and that organisations that wait are unlikely to derive any significant advantages. Organisations who have already implemented the passive approach should consider the opportunity this hybrid approach delivers for them.
For those organisations who have not yet deployed any Voice BiometricsVoice Biometrics uses the unique properties of a speakers voice to confirm their identity (authentication) or identify them from a group of known speakers (identification). solution, this hybrid approach is likely to derive greater benefits than either standalone approach and may mean that the return on investment is now far more significant.